

Hoje temos cada vez mais aplicações para resolvermos problemas envolvendo uma grande quantidade de dados. É imprescindível na hora em que vamos arquitetar os nossos sistemas, escolher os recursos de programação que irão manipular esses dados o mais eficiente possível. As técnicas de estruturas de dados nos ajudam conceitualmente nesta questão, para isso, você tem que entender como as diferentes formas de listas funcionam, bem como e onde utilizar, por exemplo, as pilhas, filas, conjuntos, etc..
As estruturas de dados são formas de distribuir e relacionar os dados disponíveis, de modo a tornar mais eficientes os algoritmos que manipulam esses dados. Existe uma grande variedade de estruturas de dados que podemos utilizar. A linguagem Java possui uma coleção completa de estruturas de dados (Collections) que podemos utilizar. Mas, é importante você entender como cada implementação funciona internamente. Só assim você vai conseguir decidir qual será a melhor opção para o programa que você está desenvolvendo.
O Java tem também outras implementações que trabalham com o conceito de key-value pairs, ou seja, cada elemento de sua lista possui uma chave e valor associado. Além da utilização de técnicas de hashing

Dentre as mais variadas utilizações das estruturas de dados, podemos destacar:
- Vetores (Arrays)
- Listas
- Listas encadeadas (Linked Lists)
- Listas duplamente encadeadas (Doubly-Linked Lists)
- Filas (Queues)
- Pilhas (Stacks)
- Conjuntos (Sets)
- Árvores (Tree)
- Tabelas espelhadas (Hash Tables)
Considerando os dados {X1, X2, X3, …, Xn) vamos ver como cada estrutura se comporta.
Vetor ou Array é uma estrutura de dados estática. Segundo DEITEL (2016, pág. 192), Arrays são estruturas de dados consistindo em itens de dados do mesmo tipo relacionados. Arrays tornam conveniente processar grupos relacionados de valores..
O acesso aos elementos de um array é por meio de índices únicos que vão de 0(zero) à “n” posições. Ou seja, o índice 1, no exemplo logo abaixo, .aponta para X2. Em resumo, é um tipo de armazenamento sequencial.

Conceitualmente, você vai se deparar com as Matrizes ( Array multi-dimensional). Em resumo, trata-se de um vetor de vetores. De acordo com DEITEL (2005, pág. 223), os arrays com duas dimensões costumam ser utilizados para representar tabelas de valores que consistem nas informações dispostas em linhas e colunas.
Identificamos os elementos da tabela através de 2 índices. Por convenção, primeiro identificamos a linha e em seguida a coluna.

Uma lista é uma série de elementos ligados. Uma lista encadeada ou lista ligada, é uma sequência finita de elementos ligadas entre si, onde uma célula da lista aponta para a próxima célula sequencialmente. As listas encadeadas são úteis para representar conjuntos dinâmicos de dados. Ou seja, você não precisa definir um tamanho máximo para uma lista.

Já a lista duplamente encadeada ou duplamente ligada, o que difere é que um elemento aponta tanto para a próxima célula quanto para a anterior.

As pilhas e as filas são consideradas listas especializadas por possuírem características de uso próprias. Seus elementos são organizados em função de um critério que regulamenta a entrada e saída dos elementos.
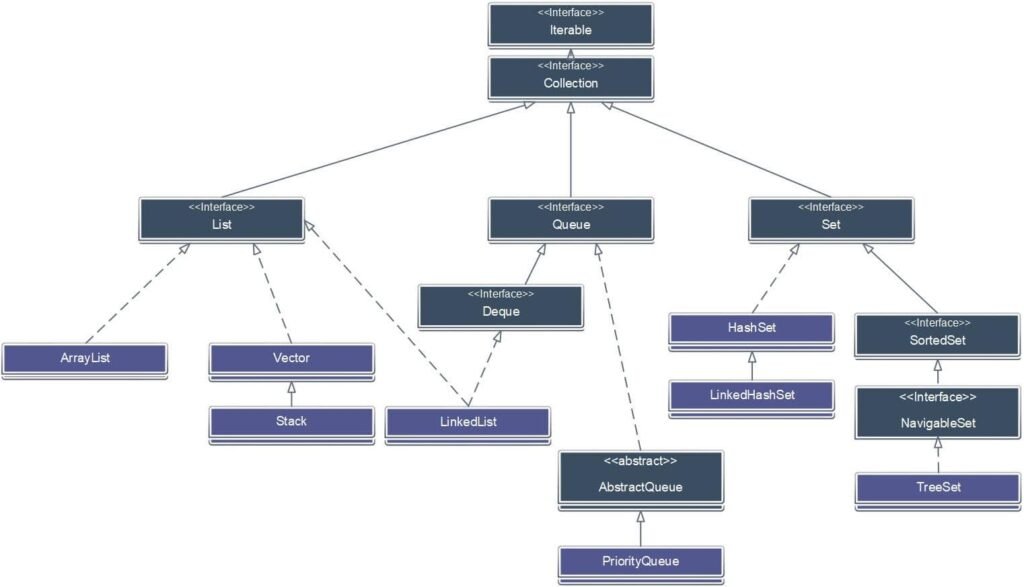
Uma fila (Queue) estabelece uma política de entrada e saída FIFO (first in, first out), ou seja, o primeiro elemento a entrar na lista é o primeiro a sair. Trata-se de uma lista encadeada onde as regras de inserção e remoção são bem definidas. Os elementos são sempre inseridos no início da lista e removidos do final da lista.
Só ressaltando, haverá situações em que você precisará mudar este comportamento e dar prioridade a um determinado elemento para que ele “fure a fila”. Para isso existe a fila de prioridades (Priority Queue) .
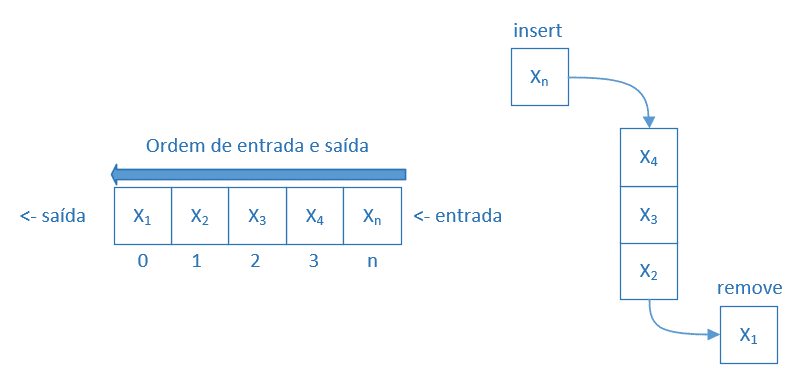
Uma pilha estabelece uma política de entrada e saída LIFO (last in, first out), o último elemento a entrar é o primeiro a sair. Os elementos são empilhados um a um. Apenas o último elemento empilhado pode ser removido da pilha, pois se tentarmos remover um elemento, por exemplo, que se encontra no meio da pilha, corremos o risco de desestruturar toda a estrutura.
Os conjuntos funcionam de forma análoga aos conjuntos da matemática, não permitem que sejam inseridos elementos duplicados num mesmo conjunto. A ordem em que os elementos são armazenados podem não ser a ordem na qual eles foram inseridos.

As Árvores são estruturas de dados baseadas em listas encadeadas que possuem um nó superior também chamado de raiz que aponta para outros nós, chamados de nós filhos, que podem ser pais de outros nós. Nas árvores os dados estão dispostos de forma hierárquica.

Este tipo de estruturas de dados é muito utilizada em banco de dados e sistema de arquivos.
Uma tabela de espalhamento também conhecida como tabela de dispersão ou tabela hash, é uma estrutura de dados especial que você pode associar chaves e valores. É uma opção de estrutura que serve para organizar e armazenar dados de forma a agilizar o processo de pesquisa. Isso ocorre porque dada uma chave, a função Hash decide em qual endereço dessa tabela aquele valor deve ser armazenado.
A função Hash tem o objetivo de distribuir valores dentro de uma estrutura em função da sua chave. Em outras palavras, a função Hash deve descobrir qual é a categoria de um determinado elemento. Para isso, ela deve analisar as características chaves do próprio elemento. Em um cenário perfeito essa operação deve ser constante ou O(1) pela notação O que, em teoria da computação é usada para descrever como o tamanho da entrada fornecido a um algoritmo qualquer afeta os recursos que o mesmo utiliza, sejam estes de memória ou tempo de execução.

Vamos pensar sobre a necessidade de otimização com o uso de hash. Imagine uma alteração de um nome qualquer de uma pessoa em uma lista encadeada de pessoas. Para encontrar a pessoa a ser modificada, é necessário percorrer a lista, na pior situação, inteira. Mesmo em estruturas de dados muito eficientes como as Árvores Binárias é necessário varrer os dados para encontrar um determinado elemento. Podemos por exemplo pegar o primeiro caractere do nome. Dessa maneira, estaremos dividindo os grupos em grupos de pessoas que começam com A, B, C, D, … O espalhamento é feito para que se tenha o menor número possível de objetos dentro de um grupo. E quando você efetuar a busca, ao invés de varrer a lista inteira, o algoritmo vai direto para o grupo, otimizando assim o resultado.

Perceba que até o momento estamos analisando os diversos mecanismos de organização de dados para atender a diferentes requisitos de processamento em um nível bastante abstrato. Sobre esses dados, podemos efetuar diversas operações como por exemplo:
- inserir valor no início da lista;
- inserir valor no fim da lista;
- inserir valor em uma posição específica de um index;
- remover o primeiro elemento;
- remover um elemento em uma posição específica de um index;
- remover o último elemento;
- retornar um elemento em uma posição específica de um index;
- verificar se a lista está vazia, etc…
É sobre essas operações que medimos a complexidade dos algoritmos e por consequência, conseguimos medir, neste caso, a eficiência das estruturas desses tipos abstratos de dados em relação às suas implementações e deste modo, podemos decidir qual estrutura de dados utilizar em nossas soluções.
Este é um tema muito abrangente e, ao mesmo tempo, muito interessante. Não acaba por aqui, veja outros artigos da Jornada do Programador e nos vemos no próximo artigo. Até lá!
Confiança Sempre!!!
Referência de material com autoria conhecida:
MANDAWALLI, Felipe. Pagar para fazer trabalho acadêmico é ilegal. Disponível em: <https://blog.mettzer.com/fraude-academica-e-ilegal/> Acesso em: 23 de junho de 2017
Referência de material sem autoria conhecida:
BLOG METTZER. Pagar para fazer trabalho acadêmico é ilegal. Disponível em: <https://www.ime.usp.br/~pf/analise_de_algoritmos/aulas/Oh.html> Acesso em: 01 de outubro de 2018
Referências:
- R. Sedgewick and K. Wayne, Algorithms, 4th Edition, Addison-Wesley, 2011.
- P. Morin, Open Data Structures: An Introduction, AU Press, 2013
- Thomas Cormen; Charles Leiserson and Ronald. Rivest, Algoritmos Teoria e Prática, Elsevier, 2012.
- C.L. Lucchesi e T. Kowaltowski, Estruturas de Dados e Técnicas de Programação, versão 1.12, agosto de 2004, Instituto de Computação, UNICAMP.
- B. Miller, D. Ranum, Problem Solving with Algorithms and Data Structures, interactive course using Python.
- I.C. Garcia, P.J. Rezende, F.C. Calheiros, Astral: Um Ambiente para Ensino de Estruturas de Dados através de Animações de Algoritmos, Unicamp, 2008.
Walmir Silva
Olá! Sou Walmir, engenheiro de software com MBA em Engenharia de Software e o cérebro por trás do GrowthCode e autor do livro "Além do Código". Se você acha que programação é apenas sobre escrever código, prepare-se para expandir seus horizontes. Aqui, nós vamos além do código e exploramos as interseções fascinantes entre tecnologia, negócios, artes e filosofia. Você está em busca de crescimento na carreira? Quer se destacar em um mercado competitivo? Almeja uma vida mais rica em conhecimento e realização? Então você chegou ao lugar certo. No GrowthCode, oferecemos insights profundos, estratégias comprovadas e um toque de sabedoria filosófica para catalisar seu crescimento pessoal e profissional.
otimo
Obrigado!
Obrigada!
Eu que agradeço! Bons estudos!
Excelente conteúdo! Possui algum artigo falando sobre a implementação das estruturas de dados passadas aqui? Obrigado!
Opa! Obrigado!
Tem esse outro que abordo com PHP mas que pode ser adaptado a qualquer outra linguagem OO facilmente:
https://growthcode.com.br/programacao/pilha-estrutura-de-dados-em-php-orientado-a-objetos/