


Atualizado pela última vez em 1 de novembro de 2023
As médias, como explorado em nosso artigo anterior, servem como pilares fundamentais na compreensão e interpretação de conjuntos de dados. Neste segmento, aprofundaremos nossa exploração sobre outras métricas de tendência central cruciais para a Ciência de Dados e Machine Learning.
No decorrer deste artigo, exploraremos a Mediana, crucial para compreender a tendência central dos dados, e a Moda, que ilustra o valor mais frequente em um conjunto, revelando insights sobre a recorrência. A Média Móvel também será um ponto de foco, sendo essencial para identificar tendências em séries temporais ao suavizar as flutuações de curto prazo.
Mediana
A Mediana é uma métrica estatística que tem sido utilizada há séculos para entender a distribuição de conjuntos de dados. A ideia de encontrar um valor central em um conjunto de dados tem uma longa história, e a formalização do conceito de mediana ocorreu no século XIX, proporcionando uma maneira robusta de representar dados, especialmente em face de outliers.
A mediana é definida como o valor que separa a metade superior da metade inferior de uma amostra de dados, uma população ou uma distribuição de probabilidade. Em um conjunto de dados, pode ser considerado o valor “do meio”. Ou seja, ela é calculada de maneira bastante simples: para um conjunto de dados ordenado, se o número de observações for ímpar, a mediana é o valor no meio do conjunto; se o número de observações for par, a mediana é a média dos dois valores no meio.
Com os dados ordenados em ordem crescente, basta analisar se é impar ou par e aplicar suas respectivas fórmulas:
- Para um número ímpar de observações:

Onde n é o número total de observações no conjunto de dados.
Veja um exemplo simples: para o conjunto de dados [3, 5, 7, 9, 11], como você já sabe, n=5 (ímpar), então a posição da mediana é (5 + 1) / 2 = 3. Logo, o valor da mediana é 7.
- Para um número par de observações:

Exemplo: para o conjunto de dados [2, 4, 6, 8], n=4 (par), então as posições centrais são n/2 = 2 (posição 2) e n/2 + 1 = 3 (posição 3). Ou seja, os valores obtidos destas posições são [2, 4, 6, 8], então a mediana é (4 + 6) / 2 = 5.
Acho super interessante essas sacadas matemáticas de quem criou este princípio. Na simplicidade de n/2 encontramos a primeira posição do meio — como são pares tem dois números dividindo o conjunto de dados — e, qual a posição do próximo número deste meio? Este meio inicial (n/2) somando-se mais uma posição (n/2 + 1).
Moda
A Moda é uma métrica estatística que identifica o valor mais frequente em um conjunto de dados. Historicamente, a moda é utilizada de maneira implícita em algumas situações, conforme observado em literaturas anteriores, embora sua formalização como uma métrica estatística seja mais recente em comparação com a média.
A moda é determinada coletando dados para contar a frequência de cada resultado. O resultado com a maior contagem de ocorrências é conhecido como a moda do conjunto, que também é comumente referido como o valor modal. Diferentemente da média e da mediana, a moda também faz sentido para “dados nominais” (ou seja, não consistindo em valores numéricos no caso da média, ou mesmo de valores ordenados no caso da mediana). Por exemplo, ao tomar uma amostra de sobrenomes coreanos, pode-se descobrir que “Kim” ocorre mais frequentemente do que qualquer outro nome, tornando “Kim” a moda da amostra.
A moda não possui uma fórmula específica como a média ou a mediana, por ser determinada simplesmente identificando o valor ou os valores que ocorrem com mais frequência em um conjunto de dados. No entanto, existem métodos algorítmicos para encontrar a moda, especialmente em conjuntos de dados grandes ou em distribuições contínuas. Alguns deles incluem: Histogramas, Estimativa de Densidade de Kernel (KDE), Algoritmos de Contagem de Frequência, dentre outros.
A moda é calculada de maneira relativamente simples em um conjunto de dados discreto. Por exemplo, a moda da amostra [1, 3, 6, 6, 6, 6, 7, 7, 12, 12, 17] é 6, pois o número 6 ocorre mais frequentemente do que qualquer outro número na amostra [1, 3, 6, 6, 6, 6, 7, 7, 12, 12, 17]. No entanto, em uma distribuição contínua, a moda é mais desafiadora para ser calculada diretamente, pois nenhum valor será o mesmo.
| Um conjunto de dados discreto é composto por valores distintos e separados, onde cada valor é obtido contando ou enumerando. Em outras palavras, os dados discretos podem assumir apenas valores específicos e não qualquer valor em um intervalo contínuo. Exemplo, número de alunos em uma sala de aula: {20, 21, 22, 23, …} Uma distribuição contínua, por outro lado, representa variáveis que podem assumir um número infinito de valores em um intervalo específico. Para você entender melhor, imagine que você está medindo a altura de todas as pessoas em uma cidade. As pessoas podem ter várias alturas diferentes, certo? Alguém pode ter 1,70 metros, outro pode ter 1,75 metros, e outro pode ter 1,78 metros, e assim por diante. Além disso, as alturas podem ser ainda mais específicas, como 1,701 metros ou 1,755 metros. Há uma infinidade de valores possíveis para a altura, mesmo em um intervalo limitado, como entre 1,50 metros e 2,00 metros. Essa situação é o que chamamos de distribuição contínua. Em uma distribuição contínua, os dados podem assumir qualquer valor em um determinado intervalo. |
Um ponto de observação em relação à moda é que pode existir mais de uma moda em um conjunto de dados. Quando um conjunto de dados tem mais de uma moda, ele é descrito conforme o número de modas presentes. Aqui estão os termos específicos:
- Unimodal: quando um conjunto de dados tem apenas uma moda.
- Exemplo: No conjunto de dados [2, 3, 4, 4, 5, 6], o número 4 é a moda porque aparece mais vezes do que os outros números.
- Bimodal: quando um conjunto de dados tem duas modas.
- Exemplo: No conjunto de dados [1, 1, 2, 3, 3, 4, 5], os números 1 e 3 são as modas porque ambos aparecem duas vezes, mais do que os outros números.
- Multimodal ou Polimodal: quando um conjunto de dados tem três ou mais modas.
- Exemplo: No conjunto de dados [1, 1, 2, 2, 3, 3, 4, 5], os números 1, 2 e 3 são as modas porque todos aparecem duas vezes.
- Uniforme: quando todos os valores aparecem com a mesma frequência, é dito que o conjunto de dados é uniforme e, tecnicamente, todos os valores são modas.
- Exemplo: No conjunto de dados [1, 2, 3, 4, 5], todos os números aparecem uma vez, então todos são modas.
A presença de múltiplas modas pode indicar a existência de diferentes “grupos” ou “clusters” em um conjunto de dados, e pode fornecer insights importantes sobre a estrutura e a distribuição dos dados. Por exemplo, em um conjunto de dados representando alturas de indivíduos, duas modas podem indicar dois grupos distintos de alturas na população estudada.
Média Móvel
A Média Móvel é uma técnica de análise estatística empregada para suavizar séries temporais, eliminando flutuações de curto prazo e destacando tendências de longo prazo. A ideia por trás da média móvel data de muitos anos, sendo mencionada na literatura estatística já no início do século XX. Em 1909, G.U. Yule descreveu as “médias instantâneas” calculadas por R.H. Hooker em 1901 como “médias móveis”.
| As séries temporais são conjuntos de dados coletados ou registrados em um intervalo de tempo específico. |
A média móvel é um tipo de filtro de resposta ao impulso finito, que ajuda a analisar pontos de dados ao longo do tempo. A técnica envolve a construção de uma série temporal, tomando médias de valores sequenciais de outra série temporal, uma forma de convolução matemática que resulta em uma suavização dos dados originais.
| A convolução é um conceito fundamental em matemática e engenharia, especialmente relevante no domínio do processamento de sinais e da análise de sistemas lineares. Ela representa uma maneira de combinar duas funções para produzir uma terceira função, que reflete como uma é modificada pela outra. Para contextualizar uma parte do conceito, imagine que você é um professor e está corrigindo as provas de seus alunos. Você tem uma folha de respostas (o filtro) que usará para corrigir as respostas de cada aluno (o sinal). Suponha que as respostas de um aluno sejam [1, 2, 3, 4] e sua folha de respostas seja [0.2, 0.5]. Agora, você vai “corrigir” as respostas do aluno, deslizando sua folha de respostas da esquerda para a direita, e somando as multiplicações em cada etapa. Vamos quebrar isso passo a passo: Primeiro Passo: Coloque a folha de respostas na primeira e segunda respostas do aluno. Multiplicações: 1 × 0.2 = 0.2 e 2 × 0.5 = 1 Soma resultados das multiplicações: 0.2 + 1.0 = 1.2 Segundo Passo: Deslize a folha de respostas uma posição à direita. Multiplicações: 2 × 0.2 = 0.4 e 3 × 0.5= 1.5 Soma: 0.4 + 1.5 = 1.9 Terceiro Passo: Deslize a folha de respostas uma posição à direita novamente. Multiplicações: 3 × 0.2 = 0.6 e 4 × 0.5 = 2.0 Soma resultados das multiplicações: 0.6 + 2.0 = 2.6 Agora, você tem corrigido todas as respostas do aluno com uma nova sequência de números que representa a pontuação do aluno em diferentes conjuntos de questões: Pontuações= [1.2, 1.9, 2.6] Essa nova sequência de números é o resultado da convolução do sinal (respostas do aluno) com o filtro (folha de respostas). |
Vamos considerar um exemplo real de média móvel para entender a convolução
Suponha que você é um analista financeiro e está analisando o preço diário de uma ação ao longo de 10 dias. Os preços são:
Preços = [20, 22, 24, 25, 23, 21, 20, 19, 18, 17]
Você quer suavizar esses dados para entender a tendência geral, então decide calcular uma média móvel de 3 dias.
Aqui, seu “filtro” será uma sequência de uns, dividido pelo número de elementos no filtro (3 neste caso) para obter a média:
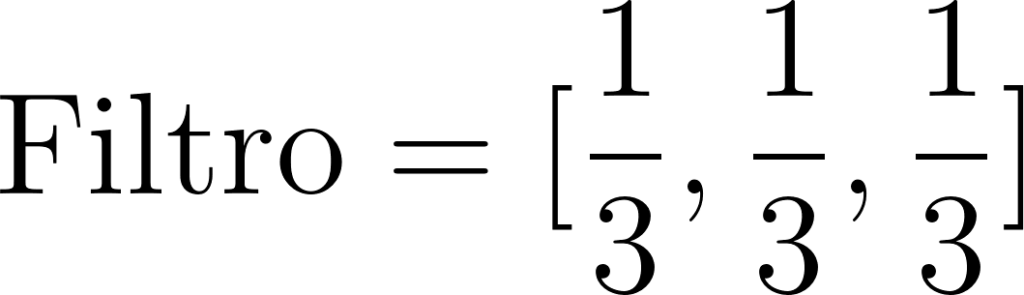
Agora, você vai “deslizar” esse filtro sobre os dados dos preços da ação, multiplicando e somando os números correspondentes, assim como fizemos no exemplo da correção das provas.
- Primeiro Passo:
- Coloque o filtro nos três primeiros preços.
- Multiplicação e soma:

- Segundo Passo:
- Deslize o filtro uma posição à direita.
- Multiplicação e soma:

(arredondado para duas casas decimais).
E assim por diante, até deslizar o filtro por todos os preços.
O resultado será uma nova sequência de números que representa a média móvel de 3 dias dos preços da ação:
Média Móvel = [22, 23.67, 24, 23, 21.33, 20, 19, 18]
Essa média móvel suavizada ajuda a ver a tendência geral dos preços da ação, reduzindo o ruído dos dados diários. O exemplo apresentado é de uma Média Móvel Simples (Simple Moving Average, SMA)
Vários tipos de médias móveis são desenvolvidos ao longo do tempo, cada um com suas próprias características e usos. Abaixo estão alguns dos tipos mais comuns de médias móveis, com uma breve explicação:
- Média Móvel Simples (SMA, Simple Moving Average): A Média Móvel Simples é calculada somando os preços (ou valores) de um número específico de períodos e depois dividindo essa soma pelo número de períodos. A fórmula é dada por:

Onde:
- n é o número de períodos
- Pi é o preço no período ii.
- Média Móvel Exponencial (EMA, Exponential Moving Average): A Média Móvel Exponencial dá mais peso aos preços mais recentes, tornando-a mais responsiva às mudanças de preço em comparação com a Média Móvel Simples. A fórmula é dada por:

Onde:
- P é o preço atual,
- n é o número de períodos,
- EMAanterio é a EMA do período anterior.
- Média Móvel Ponderada (WMA, Weighted Moving Average): A Média Móvel Ponderada atribui um peso diferente a cada preço no período de tempo considerado, geralmente dando mais peso aos preços mais recentes. A fórmula é dada por:

Onde:
- wi é o peso atribuído ao preço no período i
- Pi é o preço no período i.
- Média Móvel Suavizada (SMMA, Smoothed Moving Average): A Média Móvel Suavizada é uma variação da média móvel exponencial, mas reage mais lentamente às mudanças de preço. A fórmula é dada por:

Onde:
- n é o número de períodos
- P é o preço atual,
- SMMAanterior é a SMMA do período anterior.
- Média Móvel de Hull (HMA, Hull Moving Average): A fórmula para a Média Móvel de Hull é um pouco mais complexa, pois envolve a combinação de Médias Móveis Ponderadas (WMA) de diferentes períodos. A fórmula completa para a HMA envolve vários passos e pode ser encontrada em literatura especializada sobre o tema.
Essas fórmulas são padronizadas e amplamente aceitas na análise técnica e estatística, fornecendo uma base sólida para análise de séries temporais de dados.
Prosseguindo nos próximos artigos, discutiremos a Média Winsorizada, uma adaptação da média comum projetada para minimizar o efeito de outliers, junto com a Média Média (ou Média de Médias), útil ao analisar a média de várias médias aritméticas de diferentes amostras. Além disso, abordaremos a Média Biweight, uma média robusta e resistente a outliers, e a Média Logarítmica, que se mostra útil em contextos com dados de natureza multiplicativa ou exponencial. Estas métricas, cada uma com suas peculiaridades, são fundamentais em diferentes cenários de análise de dados, e uma compreensão aprofundada de suas propriedades e aplicações pode expandir significativamente nossa habilidade de interpretar e extrair conclusões de conjuntos de dados complexos.
Se você estiver gostando desse conteúdo, deixe o seu comentário e compartilhe com sua rede para outras pessoas interessadas em se aprofundarem no tema, tenham os benefícios deste conteúdo também. Nos vemos no próximo artigo!
Confiança Sempre!!!
Referências:
- RESEARCHGATE. An Historical Phenomenology of Mean and Median. Disponível em: https://www.researchgate.net/publication/226369756_An_Historical_Phenomenology_of_Mean_and_Median. Acesso em: XX out. 2023.
- WIKIPEDIA. Median. Disponível em: https://en.wikipedia.org/wiki/Median. Acesso em: 30 out. 2023.
- STATOLOGY. Why is the Median Important in Statistics? Disponível em: https://www.statology.org/why-is-the-median-important-in-statistics/. Acesso em: 30 out. 2023.
- JOURNAL OF STATISTICS EDUCATION. Bakker. Disponível em: https://jse.amstat.org/v11n1/bakker.html. Acesso em: 30 out. 2023.
- STATPEARLS – NCBI BOOKSHELF. Mode. Disponível em: https://www.ncbi.nlm.nih.gov/books/NBK537176/. Acesso em: 30 out. 2023.
- WIKIPEDIA. Mode (statistics). Disponível em: https://en.wikipedia.org/wiki/Mode_(statistics). Acesso em: 30 out. 2023.
- STATOLOGY. Real Life Examples: Using Mean, Median, & Mode. Disponível em: https://www.statology.org/mean-median-mode-examples/. Acesso em: 30 out. 2023.
- MCOSCILLATOR. The Origin of Moving Averages. Disponível em: https://www.mcoscillator.com/learning_center/weekly_chart/the_origin_of_moving_averages/. Acesso em: 26 out. 2023.
- WIKIPEDIA. Moving average. Disponível em: https://en.wikipedia.org/wiki/Moving_average. Acesso em: 26 out. 2023.
- SPRINGERLINK. Moving Averages. Disponível em: https://link.springer.com/referenceworkentry/10.1007%2F978-0-387-32833-1_215. Acesso em: 26 out. 2023.
- DALLASFED. Moving Averages. Disponível em: https://www.dallasfed.org/research/basics/moving.aspx. Acesso em: 26 out. 2023.
- TANDFONLINE. Moving averages methods. Disponível em: https://www.tandfonline.com/doi/abs/10.1080/03610918208812262. Acesso em: 26 out. 2023.
- CORPORATE FINANCE INSTITUTE. Moving Average – Overview, Types and Examples, EMA vs SMA. Disponível em: https://corporatefinanceinstitute.com/resources/knowledge/trading-investing/moving-average. Acesso em: 25 out. 2023.
- EMBIBE. Moving Averages: Definition, Types, Formulas, Examples. Disponível em: https://www.embibe.com/learn/maths/moving-averages. Acesso em: 25 out. 2023.
- WIKIPEDIA. Moving average. Disponível em: https://en.wikipedia.org/wiki/Moving_average. Acesso em: 25 out. 2023.
- TOKENIST. Moving Average Explained (2023): Complete Guide with Examples. Disponível em: https://tokenist.com/technical-analysis/moving-averages. Acesso em: 25 out. 2023.
- SPRINGERLINK. Types of Moving Averages. Disponível em: https://link.springer.com/chapter/10.1007/978-3-319-60970-6_3. Acesso em:25 out. 2023.
Walmir Silva
Olá! Sou Walmir, engenheiro de software com MBA em Engenharia de Software e o cérebro por trás do GrowthCode e autor do livro "Além do Código".Se você acha que programação é apenas sobre escrever código, prepare-se para expandir seus horizontes. Aqui, nós vamos além do código e exploramos as interseções fascinantes entre tecnologia, negócios, artes e filosofia.Você está em busca de crescimento na carreira? Quer se destacar em um mercado competitivo? Almeja uma vida mais rica em conhecimento e realização? Então você chegou ao lugar certo. No GrowthCode, oferecemos insights profundos, estratégias comprovadas e um toque de sabedoria filosófica para catalisar seu crescimento pessoal e profissional.
Seja o primeiro a comentar